[논문리뷰] monoMVC : Semi-supervised Monocular 3D Object Detection by Multi-Veiw Consistency (2022 ECCV)
저자 : Qing Lian, Yanbo Xu, Weilong Yao, Yingcong-Chen, and Tong Zhang
- 홍콩과기대에서 작성된 논문으로 2022 ECCV에 accept 됨
- stereo카메라 혹은 연속된 두 sequence 의 두장의 이미지 사이의 consistency가 필요하다고 주장하며 Monocular 3D Object에서 semi-supervised learning을 적용한 논문
Introduction
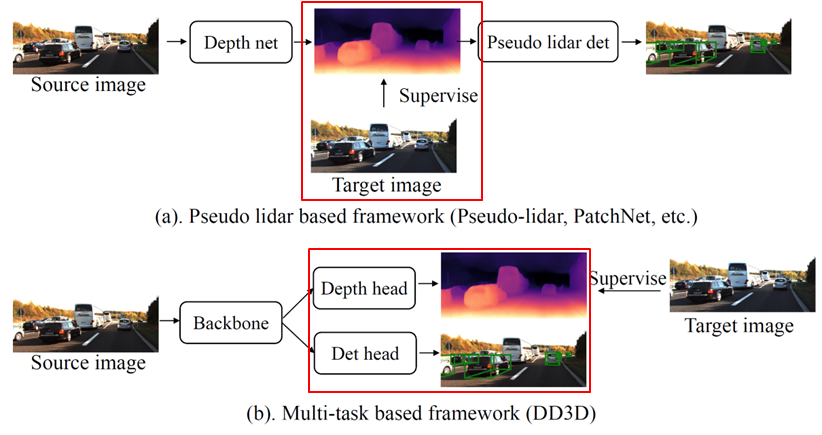
- Pseudo-lidar, Multi-task detection의 문제
- 중간 단계의 pixel-level depth representation을 3D detection으로 연결 필요
- Depth estimation, 3D detection 의 목적이 달라 supervision의 bias로 작용
- Depth-estimation - 배경과 객체의 표면에 집중
- 3D detection - object center 에 집중

- Semi-supervised in Multi-view(video), Stereo
- Foreground object에 대한 direct한 supervision을 제안
- Box-level regularization
- Object-level regularization
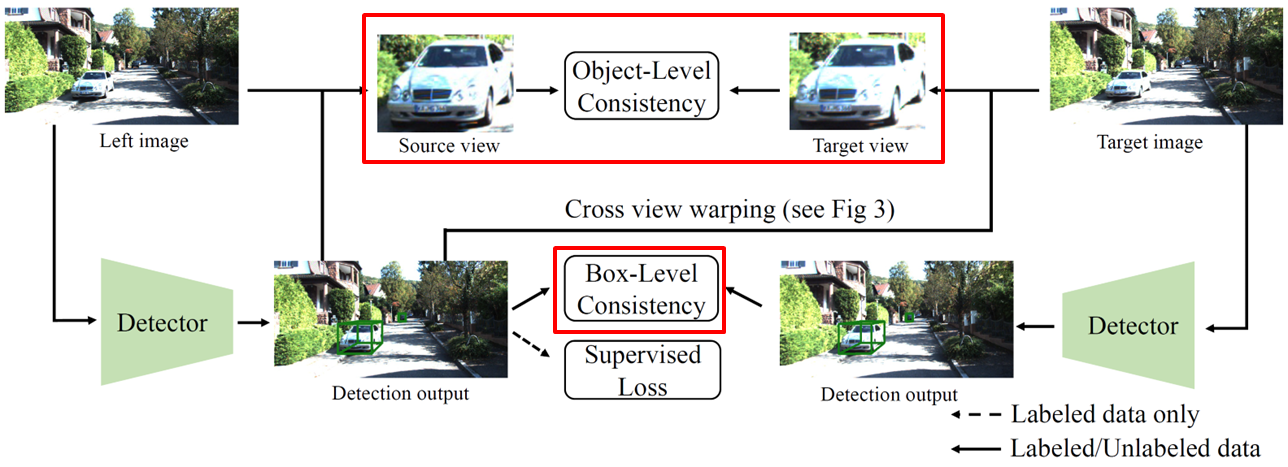
Consistency Loss
- Source view는 Stereo image 이거나, Mono에서 t-1 시점의 image로 사용 가능
- Source view(unlabel), Target view(label or unlabel) Box 예측이 유사해야 함
- Source view에서 Target view로 Projection 이후 Consistency loss 계산
- Box, Object level regularization
Box-level Consistency
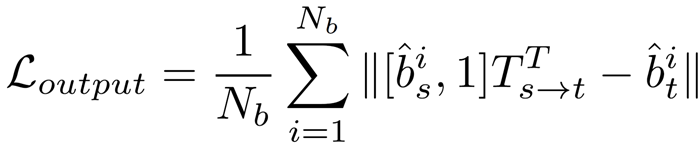
- Source box - Target 으로 Projection 시키면 Target 에서의 Box 와 같아야 함
- 2D box 를 이용하여 pixel-level 로 매칭 – 간단하고 효율적
- SSIM similarity score 를 이용하여 minimumSSIM 인 경우 matching
- confidence 0.5 이하 - 제거
Object-level Consistency
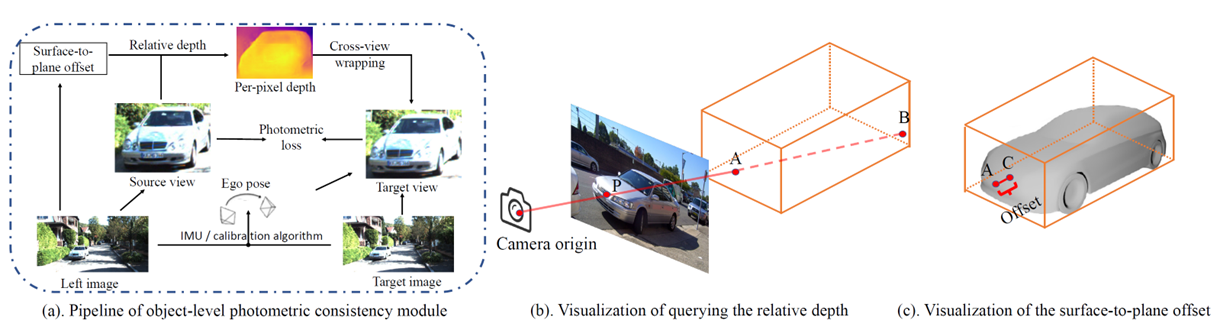
- Pixel 별 Photometric Consistency 를 통해, 더 Cense 한 Supervision
- Step1 – 3D box 생성
- Step2 – Source view 에서 Target 으로 Projection
- cube-shaped assumption
- Surface-to-cube offset head
- Step3 – Shape Uncertainty
- Laplacian distribution
Object-level Consistency – Step2
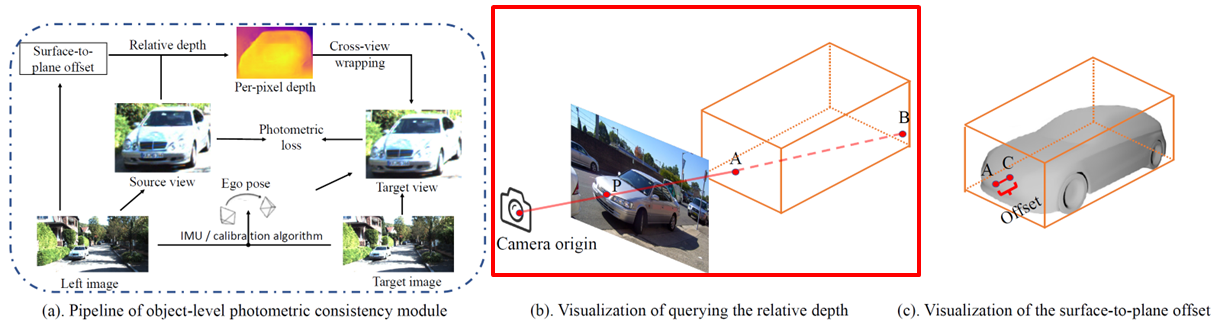
cube-shaped assumption
- 3D box를 통해 객체의 표면의 각 픽셀 depth 를 알아야 함
- Cube-shaped Assumption – 객체는 육면체라고 가정
- Camera origin $𝑜$ 에서 Source view $𝑝$ 로의 vector $𝑜𝑝$
- 생성된 box 의 각 평면 벡터 $𝑏 ⃗^𝑖𝑗$ : 외적하면 교차점
- $i$번째 box, $j$번째 방향 벡터
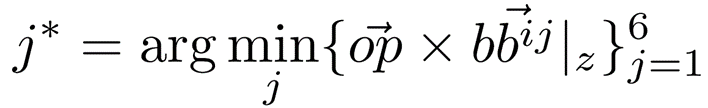
Surface-to-plane offset
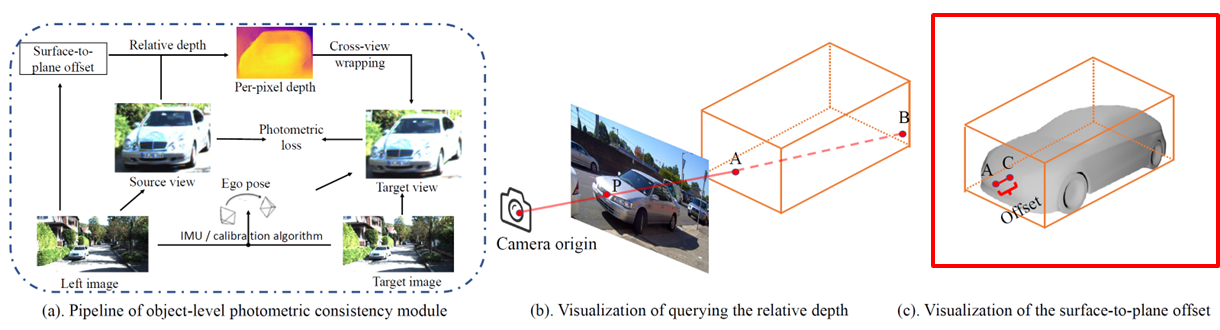
- 육면체의 평면과 Gap 이 존재
- Offset Head - 각 픽셀의 box 표면으로부터의 offset 예측
- GT가 있는 경우 box는 GT 박스를 사용하여 offset 예측
- 없는 경우는 estimated box 사용
Object-level Consistency – Step3
- object 의 몇몇 pixel – less informative, unstable when learning
- Laplacian distribution loss - 각 pixel 마다 uncertainty 함께 를 예측
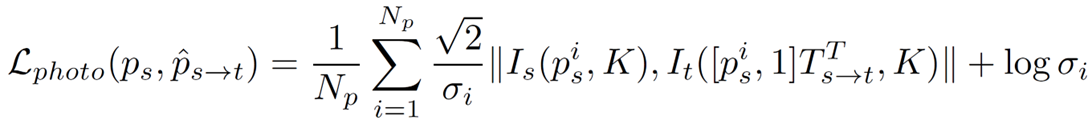
Experiments
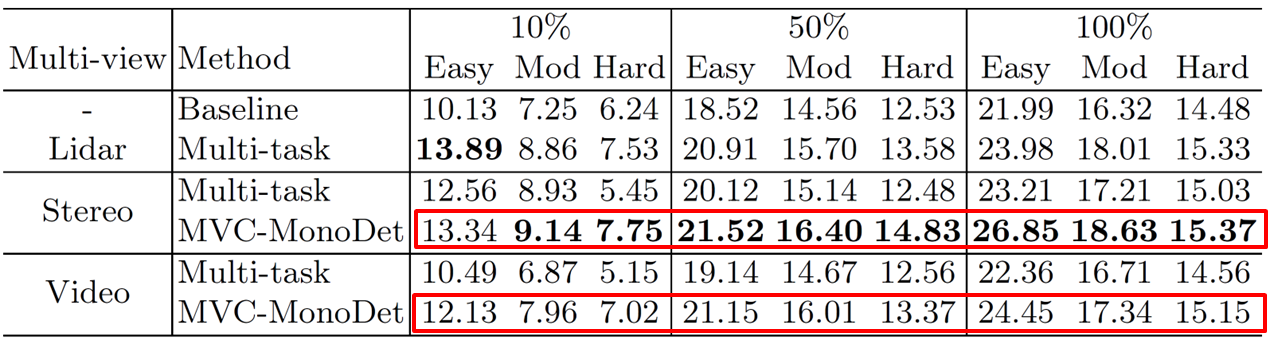
Performance of Proposed model
- Baseline – Centernet + Additional Head
- Multi-task – DD3D (with depth estimation)
Comparison with SOTA
- 기존의 다른 모델들보다 더 좋은 성능을 보여줌
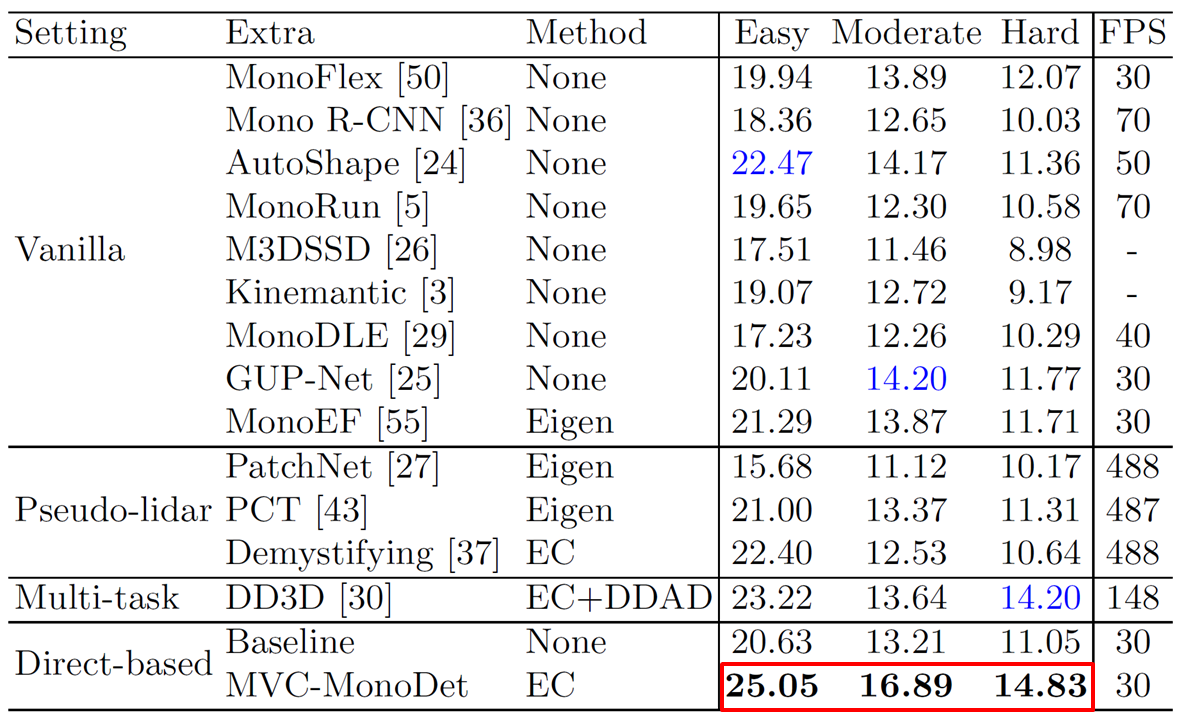
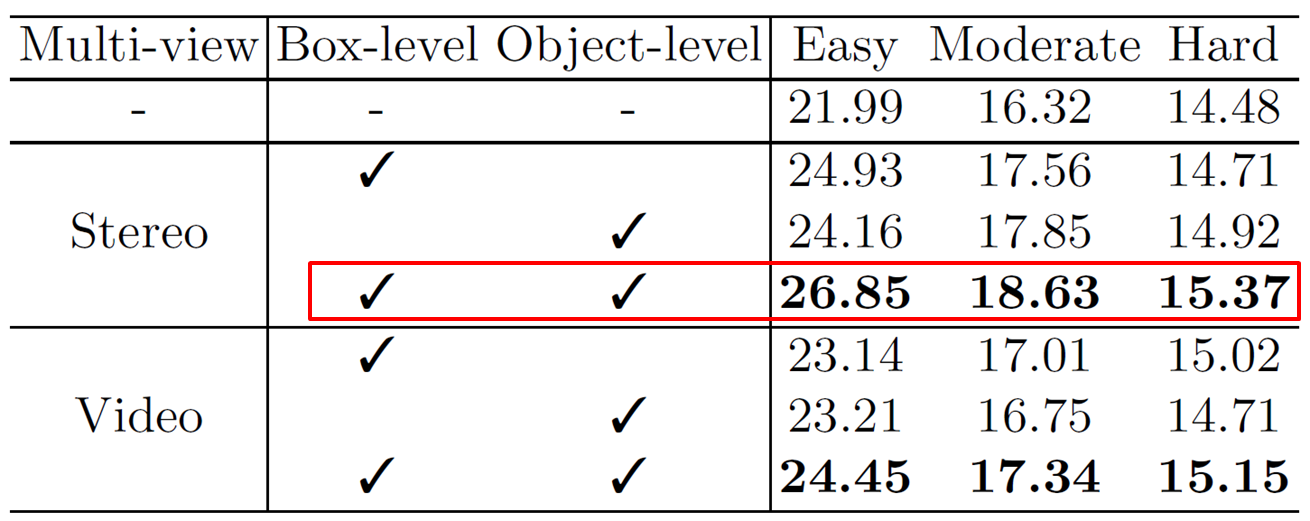
Ablation Study
- Ablation을 통해 제안한 모델의 효과를 입증하는데, 둘 중에선 box level만 사용할 때 더 좋은 성능을 보이며, video보다는 stereo에서 더 좋은 성능을 보임